
Amazon Data Firehose データストリームを Apache Iceberg 形式のテーブル配信機能を試す!
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。先日、Amazon Data Firehoseは、Amazon S3 の Apache Iceberg テーブルにデータストリームを配信できるようになりました。ETLなしでIceberg 形式のテーブルに配信できるなんてすごい!ということで、早速試してみます!
Apache Iceberg 形式のテーブルとは
Iceberg形式のテーブルは、大規模なデータレイク向けに設計されたオープンソースのテーブルフォーマットです。ACIDトランザクションのサポート、スキーマ進化、隠しパーティション、タイムトラベルなどといった、DBのストレージレイヤ管理をS3ファイルで提供します。
そのため、Amazon Athena、AWS Glue、Amazon EMRは、Amazon Redshift Spectrum などのAWSサポートはもちろん、SnowflakeやGoogle BigQueryでもサポートする今注目のテーブルフォーマットです!
当時も胸熱で書いたブログを御覧ください。
何が嬉しいのか
Apache Iceberg形式のテーブルにデータを保存できると、データレイクに対してデータベースのようにSQLだけでCRUD(Create(INSERT)、Read(SELECT)、Update、Delete)ができます。それ故にAWSにかかわらず採用が進み、様々なサービス間で横断的なデータ共有フォーマットになりつつあります。
Firehose を使用すると、ストリーミングデータを Iceberg テーブルに直接配信できます。単一のストリームから複数の Iceberg テーブルにレコードをルーティングし、Iceberg テーブル内のレコードにINSERT、UPDATE、DELETE操作を自動的に適用できます。
Firehose は、Iceberg テーブルへの 1 回限りの配信を保証します。この機能を使用するには、AWS Glue データカタログを使用する必要があります。
必要なAWSリソース
データストリームは、Direct Put、つまり、AWSCLIのコマンドでFirehose ストリームにデータを入力します。Firehose ストリームは、出力先である Iceberg 形式のテーブルに出力します。
では、この検証に必要なAWSリソースを列挙します。
- Firehose ストリーム
- S3 バックアップバケット
- ソースレコードのバックアップ用のバケットで、レコード処理の変換によって目的の結果が得られない場合でも、ソースレコードを復元できます。
- Firehose実行ロール
- Firehose ストリームが実行に必要なロールを事前に作成して設定します。
- S3 バックアップバケット
- Iceberg 形式のテーブル
- Iceberg 形式のテーブル用のバケット
- テーブルデータを格納するバケットです。
- Iceberg 形式のテーブル用のバケット
- Firehose ストリームのCloudWatch Logs ロググループ
- 実行すると自動的にログストリームが作成されます。
- エラーはこのログでトラブルシューティングできます。
データストリームを Iceberg 形式のテーブル配信機能を試す!
Iceberg 形式のテーブルの作成
Iceberg 形式のテーブルは、Amazon Athenaのクエリエディタで作成します。
CREATE TABLE weather (
device_name string,
device_ts string,
temperature int,
humidity int)
LOCATION 's3://cm-weather-tmp/weather/'
TBLPROPERTIES (
'table_type'='ICEBERG'
);
S3 バックアップバケットの作成
マネジメントコンソールから普通に作成します。
- cm-weather-backup-tmp バケット
Firehose実行ロール
下記のドキュメントに従い、以下のようなロールを作成しました。
信頼関係
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "firehose.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
インラインポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:GetTable",
"glue:GetDatabase",
"glue:UpdateTable"
],
"Resource": [
"arn:aws:glue:*:*:catalog",
"arn:aws:glue:*:*:database/*",
"arn:aws:glue:*:*:table/*/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::*",
"arn:aws:s3:::*/*"
]
},
{
"Effect": "Allow",
"Action": [
"kinesis:DescribeStream",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:ListShards"
],
"Resource": "arn:aws:kinesis:*:*:stream/*"
},
{
"Effect": "Allow",
"Action": [
"kms:Decrypt",
"kms:GenerateDataKey"
],
"Resource": [
"arn:aws:kms:*:*:key/*"
],
"Condition": {
"StringEquals": {
"kms:ViaService": "s3.ap-northeast-1.amazonaws.com"
},
"StringLike": {
"kms:EncryptionContext:aws:s3:arn": "arn:aws:s3:::*"
}
}
},
{
"Effect": "Allow",
"Action": [
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:*:*:log-group:*:log-stream:*"
]
},
{
"Effect": "Allow",
"Action": [
"lambda:InvokeFunction",
"lambda:GetFunctionConfiguration"
],
"Resource": [
"arn:aws:lambda:*:*:function:*:*"
]
}
]
}
Firehose ストリームの作成
S3 バックアップバケットとFirehose実行ロールが作成できたので、これらを使ってFirehoseストリームを作成します。
ソースはDIRECT PUT、送信先は新たに追加された Apache Iceberg テーブルです。
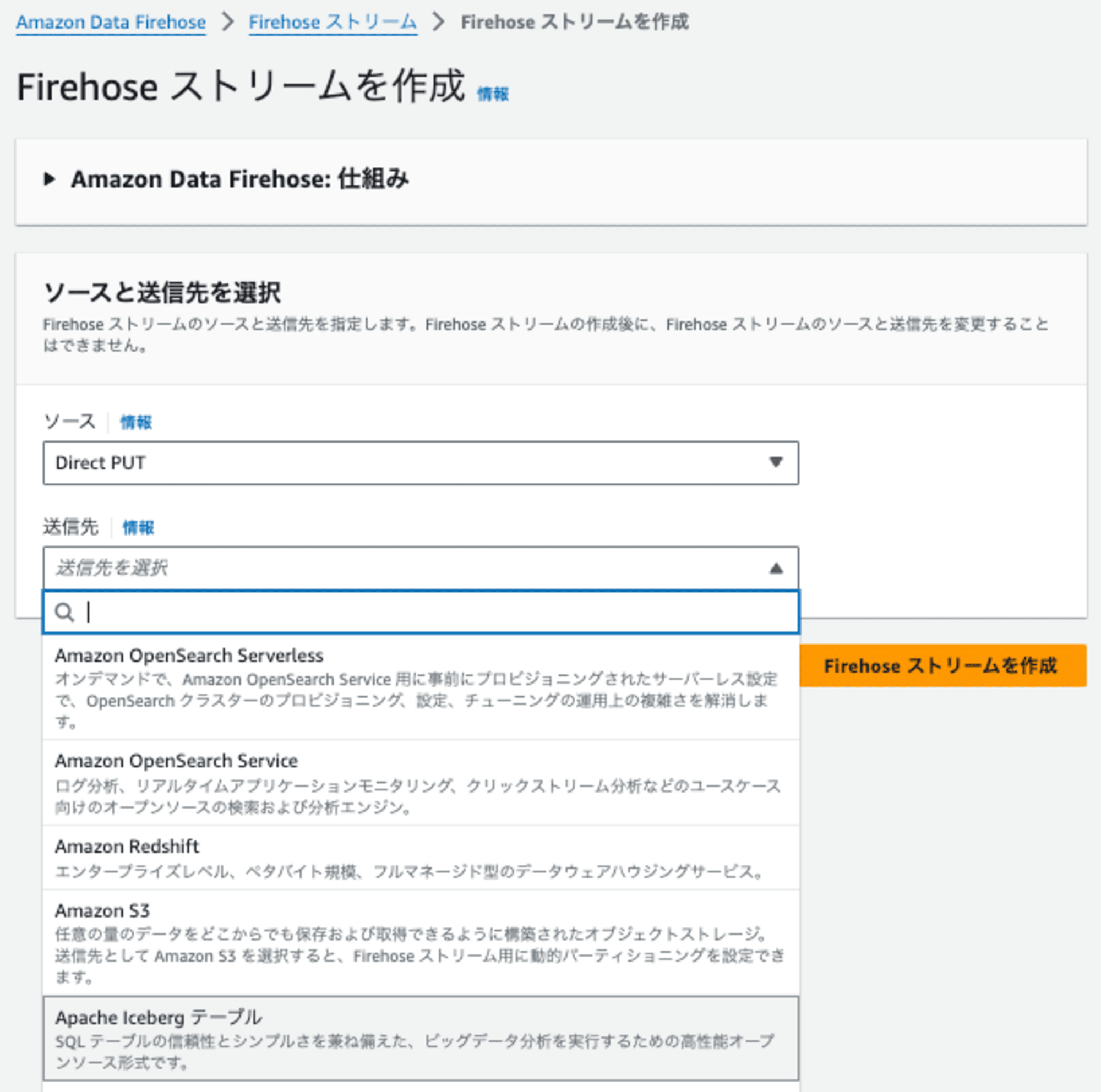
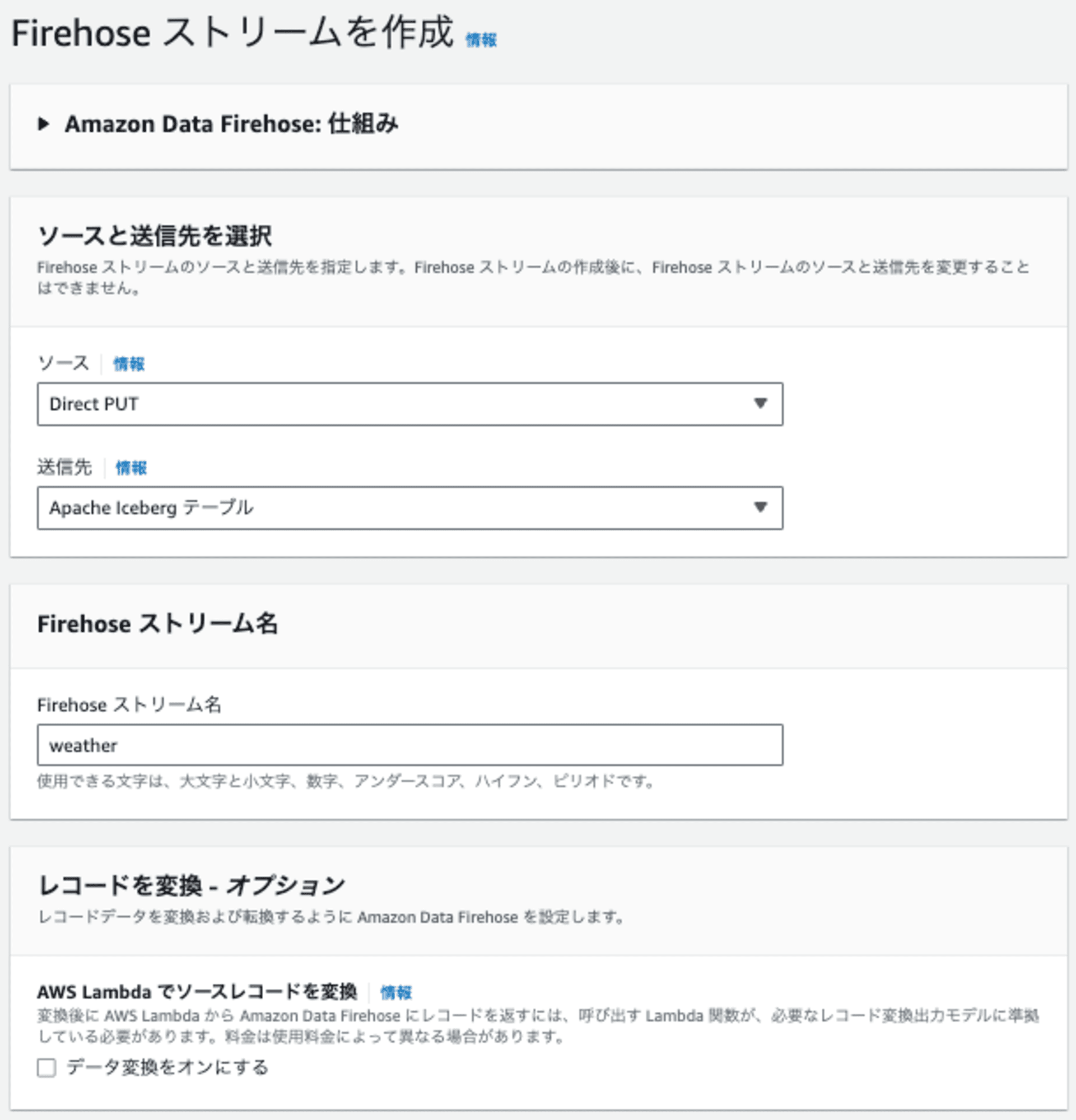
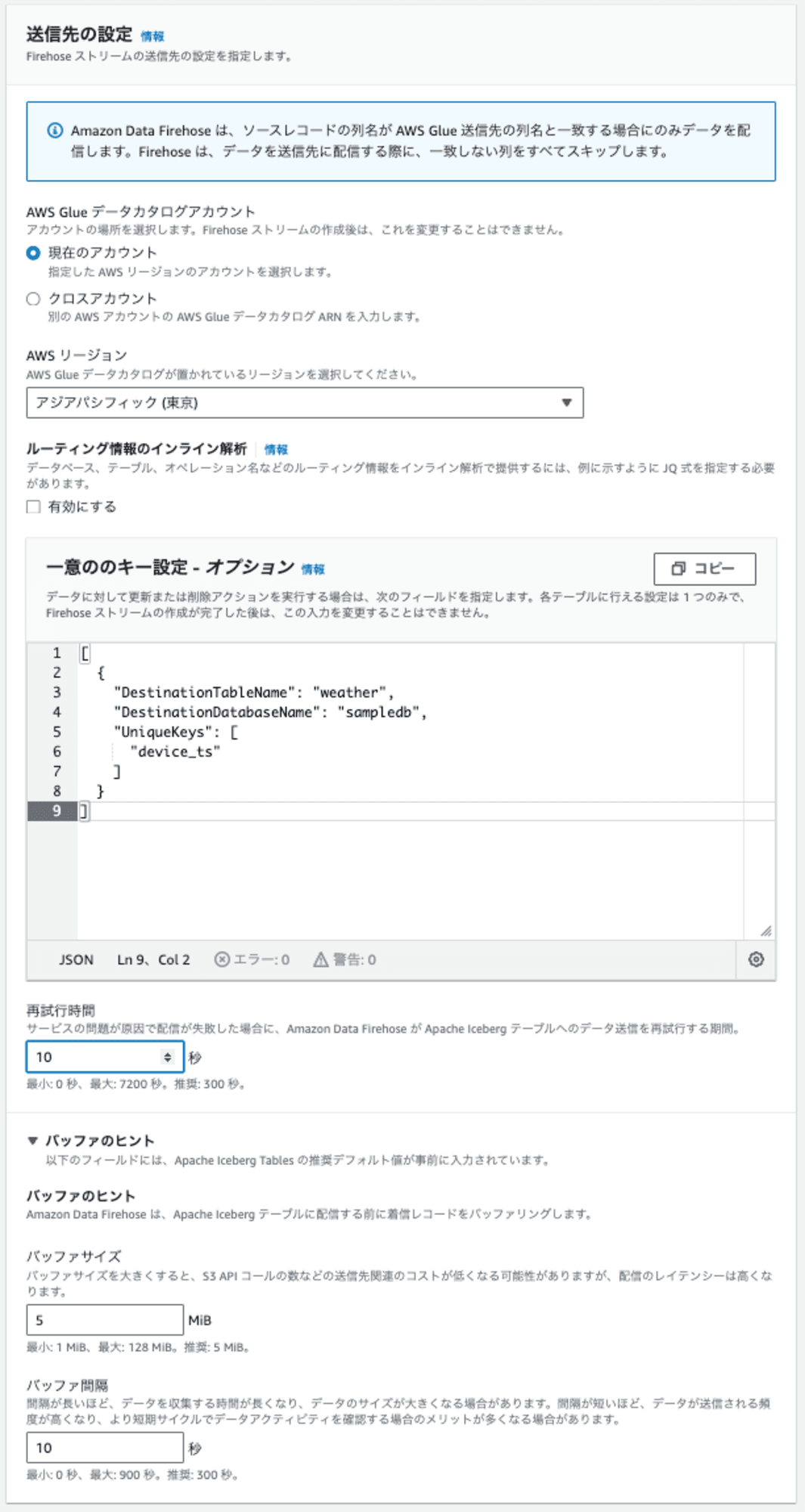
あとは、以下のように設定しました。
動作確認
今回は、バッファ間隔を10秒ごとに設定しましたので、AWSCLIのコマンドラインでDirect PUTした後、10秒程度で、レコードの追加が確認できるはずです。
AWSCLIで1レコード追加する
まずは、1レコード入れて追加します。
aws firehose put-record --cli-binary-format raw-in-base64-out --delivery-stream-name weather --record '{"Data":"{\"device_name\": \"weather\",\"device_ts\": \"2024-10-04 15:41:55\",\"temperature\": 20,\"humidity\": 58}"}'
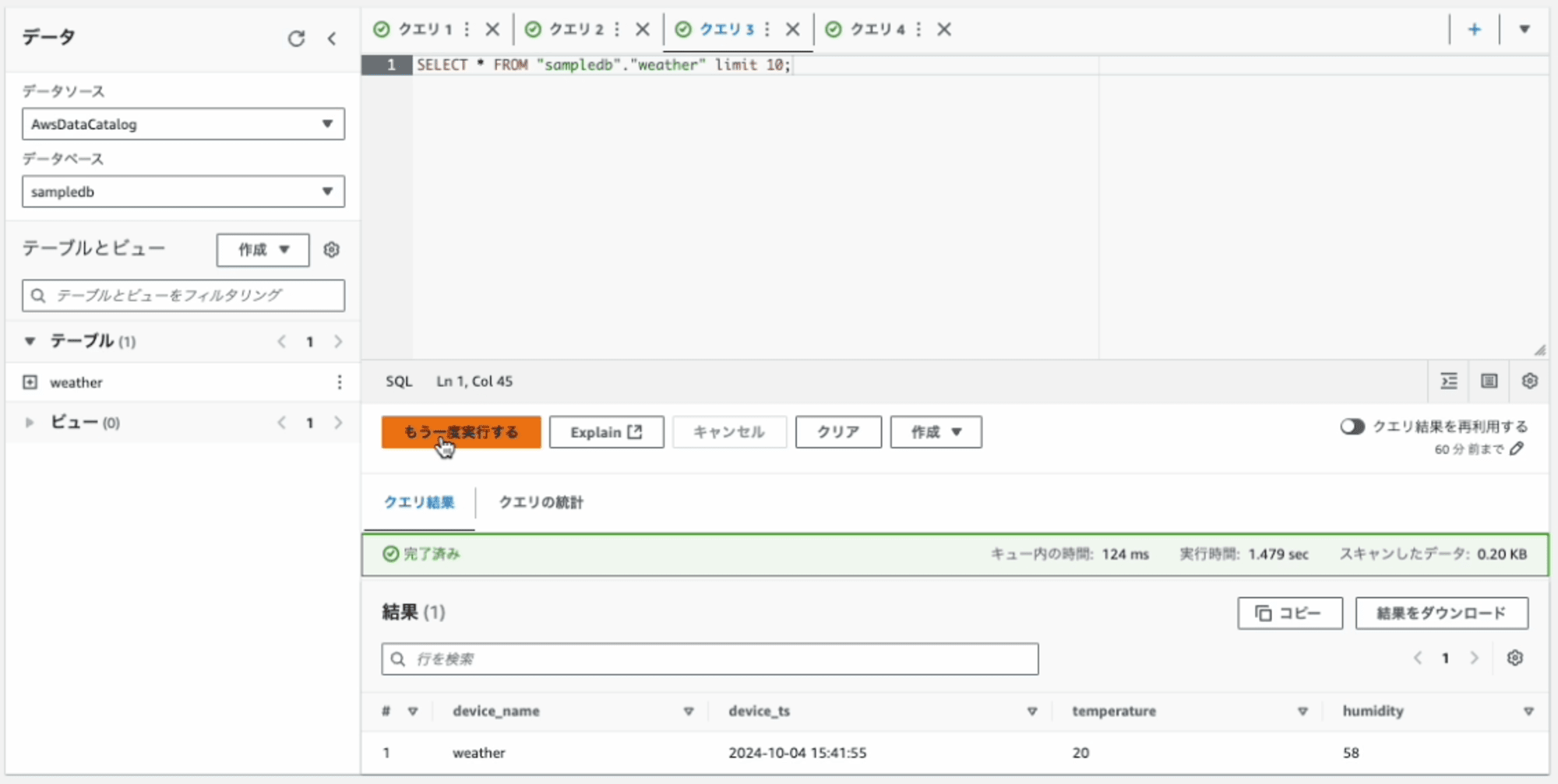
Amazon Athenaから1レコード追加されたことを確認
10秒ほど待って、確認すると追加されたことが確認できます。
AWSCLIで4レコード追加する
次は、さらに4レコード入れて連続で追加します。
aws firehose put-record --cli-binary-format raw-in-base64-out --delivery-stream-name weather --record '{"Data":"{\"device_name\": \"weather\",\"device_ts\": \"2024-10-04 15:41:56\",\"temperature\": 16,\"humidity\": 60}"}'
aws firehose put-record --cli-binary-format raw-in-base64-out --delivery-stream-name weather --record '{"Data":"{\"device_name\": \"weather\",\"device_ts\": \"2024-10-04 15:41:57\",\"temperature\": 20,\"humidity\": 46}"}'
aws firehose put-record --cli-binary-format raw-in-base64-out --delivery-stream-name weather --record '{"Data":"{\"device_name\": \"weather\",\"device_ts\": \"2024-10-04 15:41:58\",\"temperature\": 22,\"humidity\": 56}"}'
aws firehose put-record --cli-binary-format raw-in-base64-out --delivery-stream-name weather --record '{"Data":"{\"device_name\": \"weather\",\"device_ts\": \"2024-10-04 15:41:59\",\"temperature\": 24,\"humidity\": 44}"}'
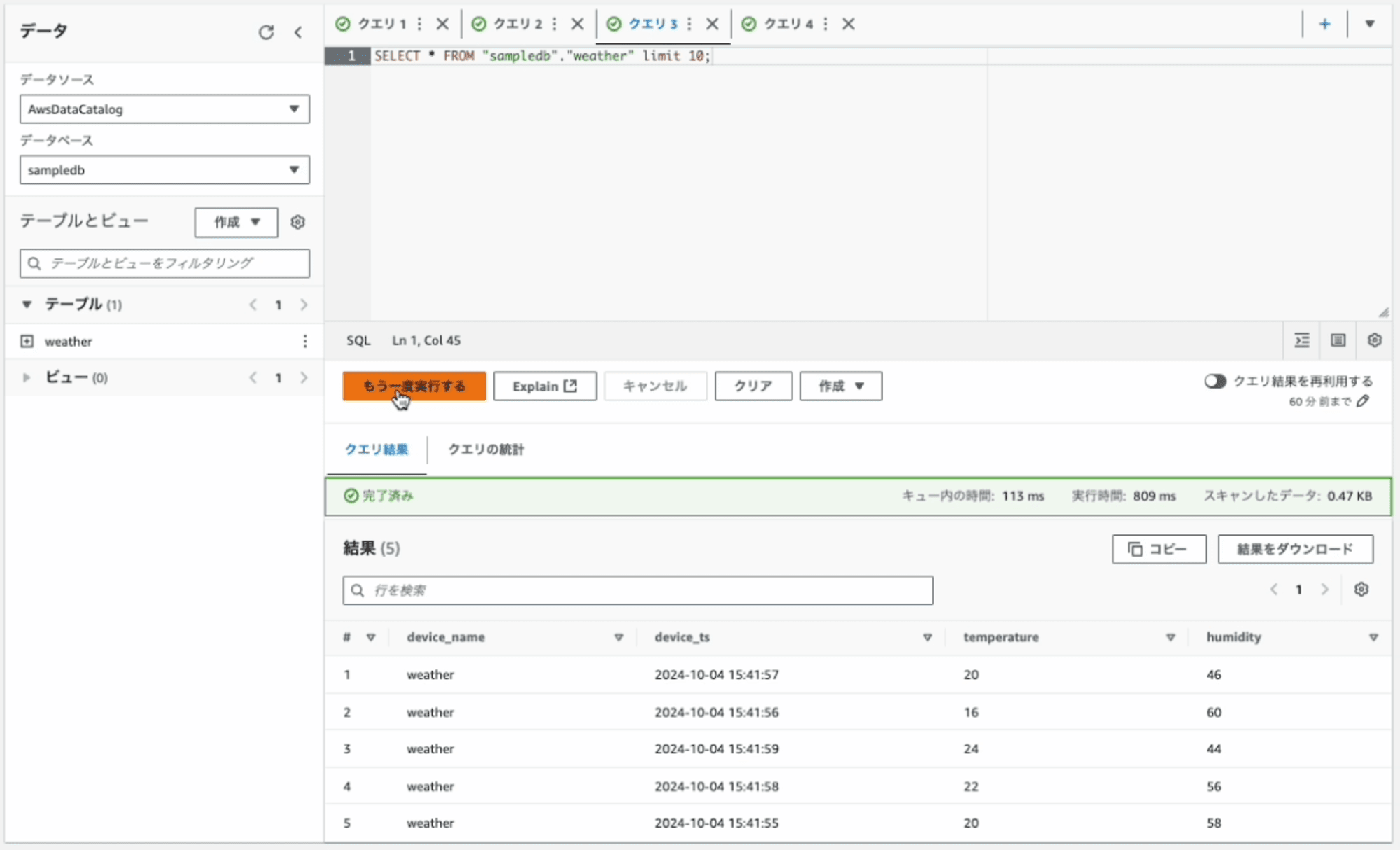
Amazon Athenaから4レコード追加追加されたことを確認
10秒ほど待って、確認するとさらに4レコード追加されたことが確認できました。
試行錯誤の末、想定通りの確認ができました。良かった。
最後に
最初は、日時カラムをIcebergのTimestamp型に格納し、そのTimestampをdate関数で変換して、Hidden Partitionで分割を試みましたが、うまくいきませんでした。その際、CloudWatch Logsのログはデバッグにとても参考になりました。
今回は、フラットなJSONのストリームをそのままIcebergテーブルに格納しましたが、ネストしたJSONのストリームや複数のIcebergテーブルへの格納も可能なようです。
データストリームを Iceberg 形式のテーブルに配信する機能は素晴らしいですが、データをレコードごとにPUTするため、小さなデータファイルがレコード数に応じて作成されます。そのため、本番運用では、Glue 等によるテーブル最適化機能と組み合わせることが必要になります。下記のブログでは、AWS Glue データカタログによる Apache Iceberg テーブルのストレージ最適化の方法をご紹介しています。










